
过去一个月了在FPGA市场繁荣。在这篇文章中,我们将简要分析三个车库从Xilinx fpga,英特尔半导体晶格。
这些设备集中于提高性能的不同方面:Xilinx VU57P试图规避要求应用程序中的内存带宽的挑战。英特尔Stratix 10 NX FPGA结合AI-optimized DSP模块来帮助实现低延迟的大型人工智能模型。,晶格Nexus fpga试图重新定义低功耗,小fpga的形式因素。
这些设备能告诉我们有关fpga方向的吗?
Xilinx VU57P FPGA-High-Bandwidth记忆
在过去的十年里,许多应用领域的计算带宽呈指数增加。例如,DSP片的数量Xilinx FPGA提供了机器学习应用程序从大约2000片增加最大的Virtex 6 FPGA约12000片在现代Virtex UltraScale +设备。观察到类似的趋势在其他应用领域如网络技术和视频应用程序如下所示。
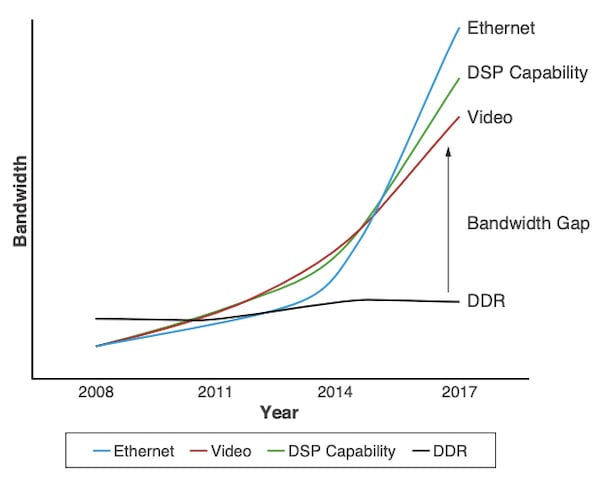
内存带宽的要求。图像使用的赛灵思公司
上面的图显示的内存带宽DDR技术仅略有增加了在过去十年约2倍DDR3 DDR4。(值得注意的是从DDR4 DDR5可能更有效。)
带宽图中描述的差距意味着有限的FPGA和内存之间的数据传输速率是这些应用的一个瓶颈。为了解决这个问题,设计师通常采用几个DDR芯片并行增加内存bandwidth-not一定是内存容量。然而,这种方法就禁止以上的内存带宽85 GB / s因为功耗大、形式因素,和成本问题以及PCB设计的挑战。
此外,一个有效的解决内存带宽问题是DRAM-based内存类型称为高带宽内存(HBM)。在这种情况下,硅堆技术是利用FPGA实现DRAM内存和彼此在同一个包旁边如下描述。
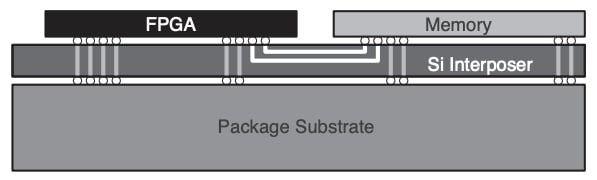
硅堆有助于实现DRAM内存和FPGA并排。图像使用的赛灵思公司
HBM技术允许我们消除相对较长的PCB DDR芯片连接到FPGA的痕迹。使用一个集成的HBM接口与大量的针导致大幅提高内存带宽的延迟类似DDR-based技术。
Xilinx已经最近发布了VU57P FPGA(从Virtex UltraScale +系列)包含16 G HBM内存带宽高达460 GB / s。雇佣了一个集成AXI端口的设备开关,让我们从任何内存端口访问任何HBM内存位置。
除了低功耗计算能力和大内存带宽上面所讨论的,VU57P提供高速接口,如以太网与RS-FEC 100克、150克茵特拉肯,作为PCIe Gen4。58 g PAM4收发器的新设备支持连接到最新的光学标准。这可以帮助下一代防火墙和交换机和路由器等不同的应用程序和QoS。
英特尔Stratix 10 NX FPGA-AI-Optimized DSP块
许多传统的应用程序需要高精度的数字信号处理(DSP)算术。这就是为什么fpga通常与高精度乘数DSP模块和蛇。例如,XC7A50T (Xilinx)和5 cgxc4(英特尔)分别有120和140的18 x 18乘数。
原来较低的比特数可用于实现许多深度学习应用程序没有显著影响信息的准确性。lower-precision近似减少计算资源的数量以及所需的内存带宽。
降低位宽的另一个优点是节电的lower-precision计算和小需要传输的比特数为每个内存事务。事实上,有许多深刻的学习应用,INT8甚至低精度计算会导致可接受的结果,根据加州大学戴维斯分校的研究人员。
的英特尔Stratix 10 NX fpga是第一个从英特尔AI-optimized fpga。这些设备将算术阻塞称为AI张量包含一系列密集的乘数精度低。这些块的基本精度INT8 INT4,尽管他们通过shared-exponent FP16和FP12数值格式支持的硬件。
一个AI张量块(受雇于Stratix 10 NX FPGA)可以增加INT8吞吐量15倍与DSP相比标准的英特尔Stratix 10块FPGA。AI张量块的高层框图如下所示。
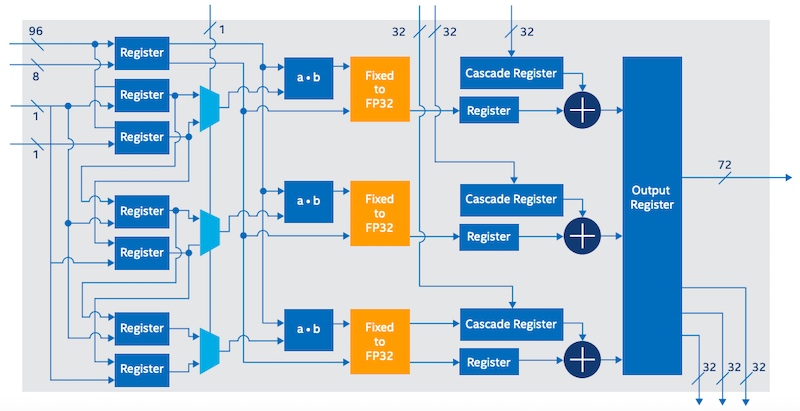
框图AI的张量。图像使用的英特尔
最具特色的英特尔Stratix 10 NX FPGA的特性是其提供的高计算密度AI-optimized计算模块。然而,新设备包含两个功能,进一步帮助设计师实现它大型人工智能模型在低延迟:它支持丰富near-compute内存(集成HBM)和高带宽网络(57.8 G PAM4接收器)。
fpga晶格Nexus-Low-Power、小形式因素
晶格半导体最近发布了Certus-NX FPGA的家庭使用28 nm完全耗尽的绝缘体(FD-SOI)过程技术。FD-SOI,最初是由三星,有点类似传统的CMOS工艺;然而,它使大量的晶体管的一个可编程的偏见所示的概念上。

晶格Nexus的电路架构平台。图像(修改)的使用晶格半导体(PDF)
一个可编程的大部分电压使显著减少芯片面积和功耗。Certus-NX的功耗减少四倍比其他同样数量的fpga逻辑细胞。
由于采用FD-SOI技术、新设备可以包小至6毫米x 6毫米,并提供两倍的I / o每毫米2而类似的fpga。下表比较了Certus-NX-40英特尔和Xilinx的类似产品。
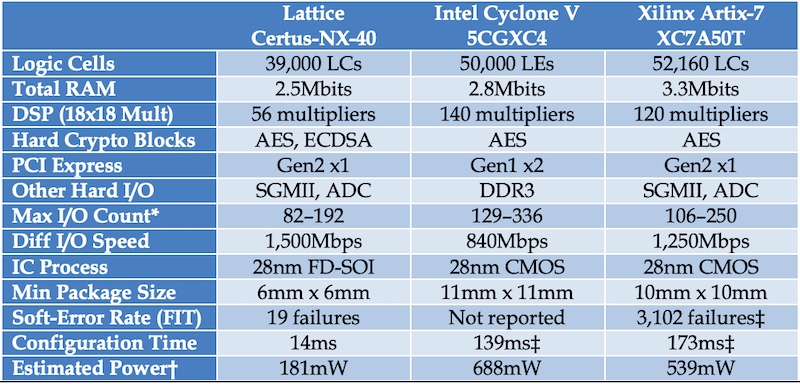
比较三种流行的作为PCIe fpga设计。图像使用的晶格半导体(PDF)
请注意,大部分的新设备支持AES加密和椭圆曲线(ECDSA)进行身份验证。因此,它为网络设备可以提供更高的安全性。此外,它表现出更高的免疫软错误,这使得新设备适合于航空航天应用。
fpga是如何被优化
通过检查这些出版从Xilinx fpga,英特尔半导体晶格,我们可以看到一个清晰的愿景fpga如何发展浓度高内存带宽,人工智能优化、低功耗和小形式因素。
你直接与fpga工作吗?你见过这种技术如何发展多年来吗?在下面的评论中分享你的想法。





